Our Products
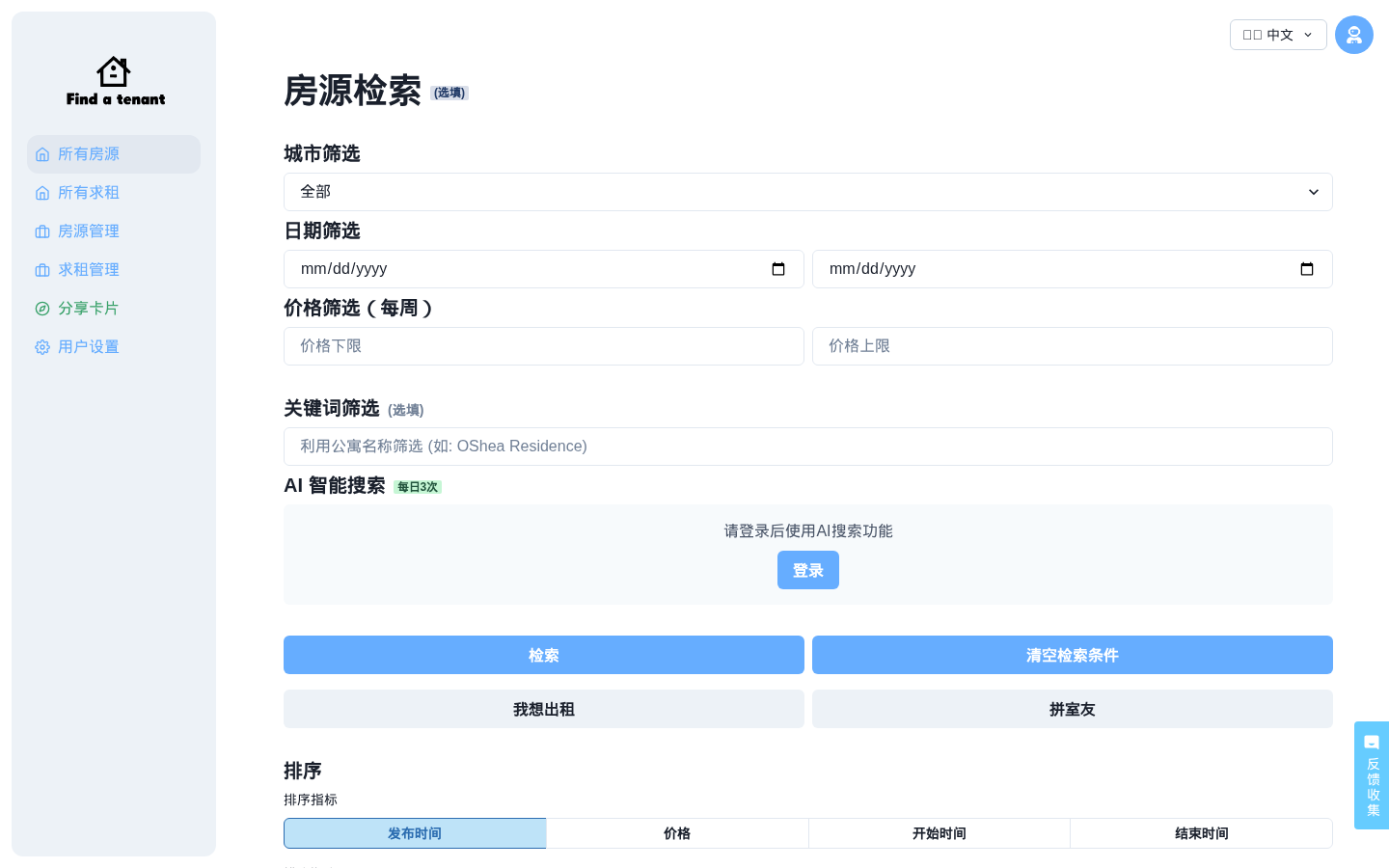
Find-A-Tenant
Find-A-Tenant is an AI-powered rental assistant for international students in the UK. Instead of filling out rigid search filters, users describe their ideal home in everyday language — and the AI matches them with suitable listings.Find-A-Tenant 是面向英国留学生的 AI 智能租房助手。用户无需填写精确的筛选条件,只需用日常语言描述理想中的房子,AI 就能自动匹配合适房源。在 Airbnb 之前就实现了 AI 找房。
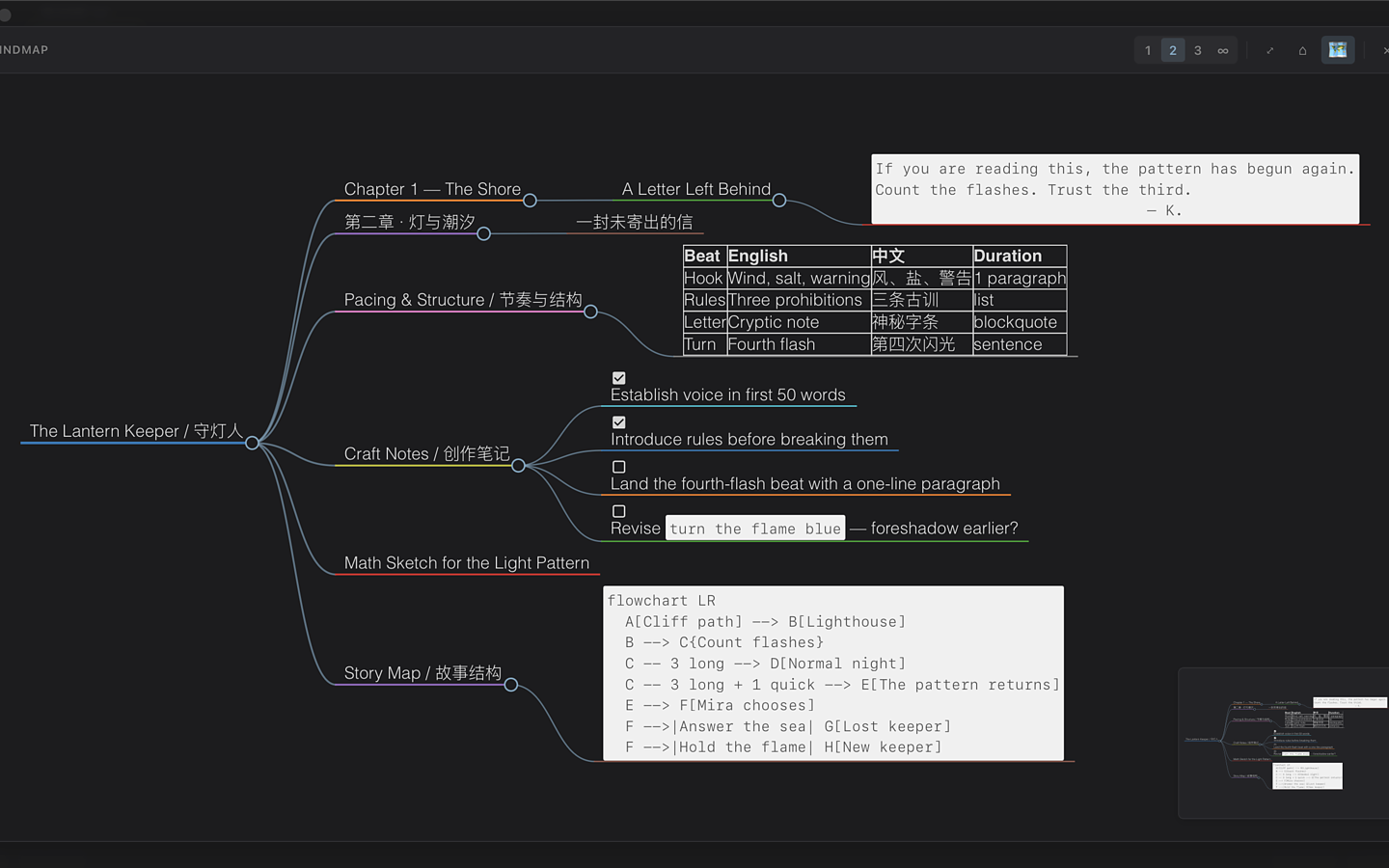
Novelist
Novelist is a lightweight, extensible writing app for long-form creators. It stays fast on large manuscripts, supports CJK writing from the start, and combines a focused editor with plugins, export workflows, mind maps, and reviewable AI writing assistance.Novelist 是一款面向长篇创作者的轻量、流畅、可扩展写作工具。它在超大文稿中保持顺滑,从一开始就重视中日韩写作体验,并把专注编辑器、插件、导出、思维导图和可审阅的 AI 改稿流程整合在一起。
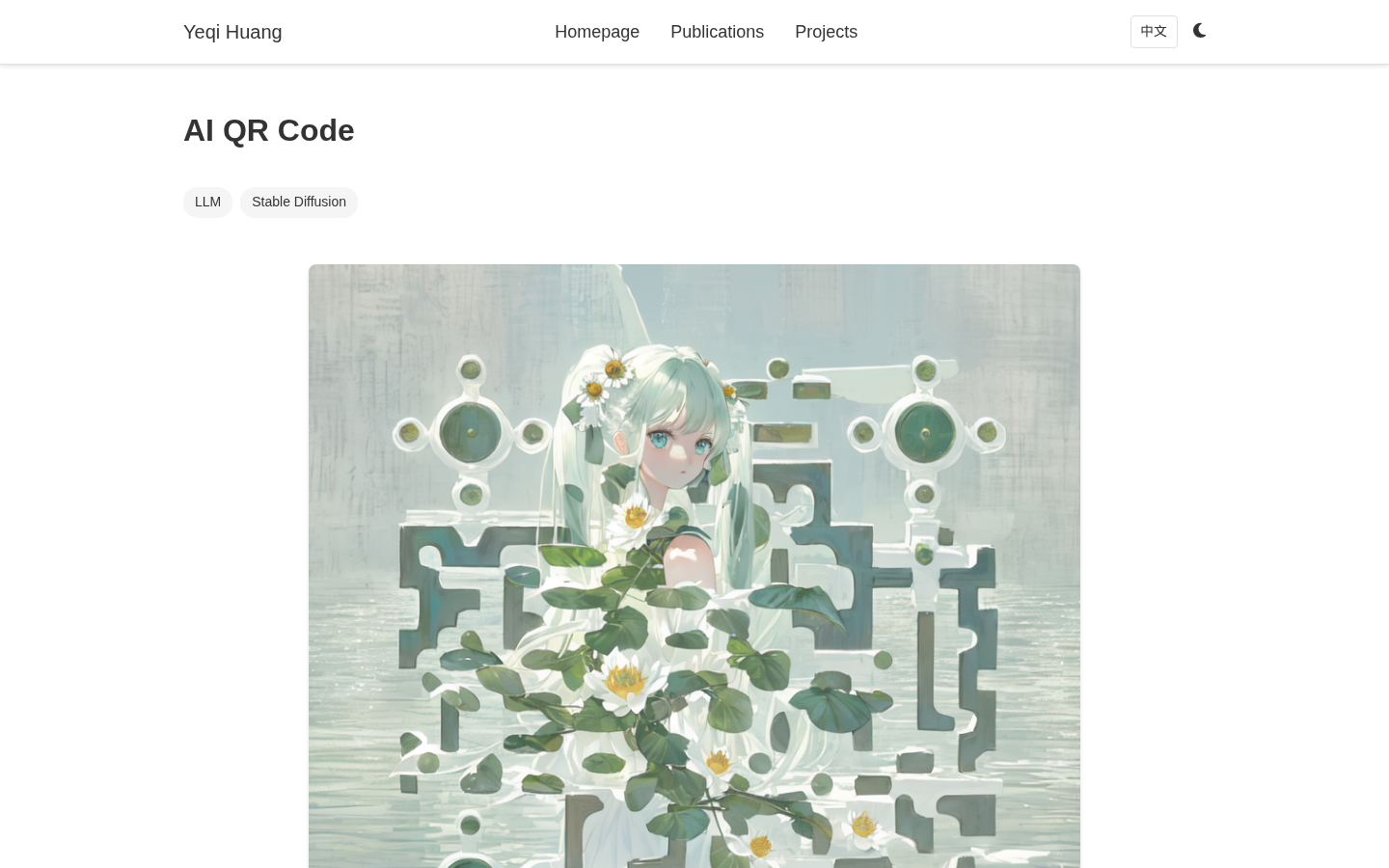
AI QR Code
AI QR Code generates artistic QR codes using AI, with a breakthrough capability: embedding multiple independently scannable QR codes within a single cohesive artwork. The signature feature — couple QR codes — places two people in one image, each with their own scannable code linking to different content.AI QR Code 使用 AI 生成艺术二维码,独创突破性方案:在一张完整的 AI 艺术画面中嵌入多个独立可扫描的二维码。核心卖点——情侣二维码:一张画面、两个人、两个码,扫出来内容不同。
AI4Whisky
AI4Whisky is an AI-powered carbon intelligence platform for the Scotch whisky industry. It helps distilleries standardise Scope 1, 2, and 3 carbon calculations, simplify data input, identify emission hotspots, and generate practical reduction guidance toward the sector's Net Zero 2040 commitment.AI4Whisky 是面向苏格兰威士忌行业的 AI 碳智能平台。它帮助酒厂标准化 Scope 1、2、3 碳排放计算,简化数据录入,识别排放热点,并生成面向 Net Zero 2040 目标的可执行减排建议。

DeepReader
DeepReader is your AI reading companion. It automatically aggregates book reviews from multiple platforms and provides an AI partner for in-depth book discussions. Read a book and want to know what others think? DeepReader collects reviews from Douban, Bilibili, and YouTube, then lets you discuss any book with AI anytime.DeepReader 是你的 AI 读书搭子——自动聚合多平台书评,AI 陪你聊书。读完一本书后,想看看别人怎么评价、想找人聊聊书中观点?DeepReader 用 AI 帮你搞定这一切。

BTMR Paper Extractor
BTMR Paper Extractor is an AI-powered reading assistant that transforms complex academic papers into easy-to-read structured summaries. Built as a Cerebras Hackathon project, it supports importing from ArXiv links, PDF uploads, and web URLs, then automatically generates digestible summaries exportable as HTML and PDF.BTMR Paper Extractor 是一款 AI 论文阅读助手,把复杂论文变成易读的结构化摘要。作为 Cerebras Hackathon 参赛项目,支持从 ArXiv 链接、PDF 文件、网页等多种来源导入论文,AI 自动生成结构化摘要,支持导出为 HTML 和 PDF。
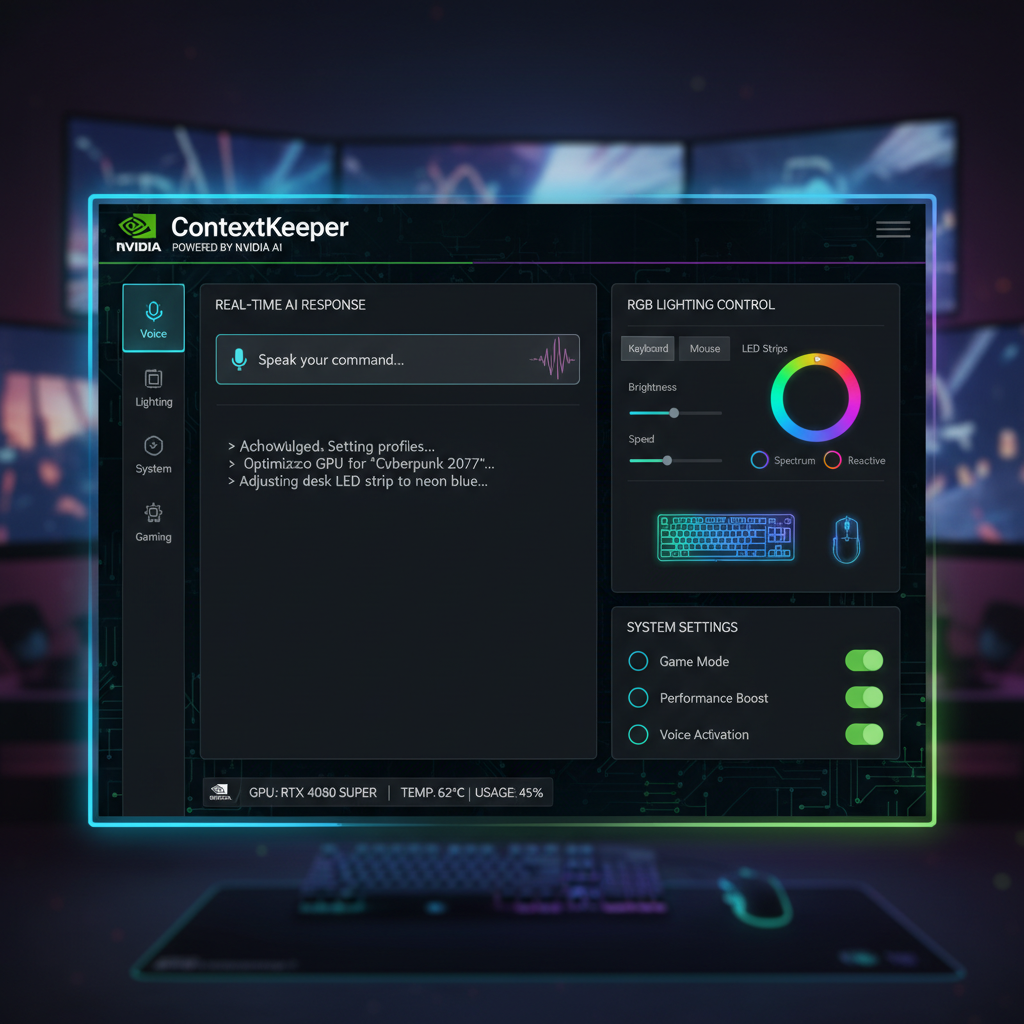
ContextKeeper
ContextKeeper is a local AI assistant that lets you control your PC with voice or text commands — adjusting system settings, game parameters, and peripheral lighting. Built on NVIDIA's G-Assist platform, it runs entirely on your local RTX GPU with no cloud dependency, ensuring privacy and fast response times. It placed 4th at the NVIDIA G-Assist Hackathon and is listed on the NVIDIA Store.ContextKeeper 是一个本地 AI 助手,用说话或打字的方式控制电脑——调系统设置、游戏参数、外设灯光。基于 NVIDIA G-Assist 平台,运行在本地 RTX 显卡上,不需要联网,隐私安全、响应快速。在 NVIDIA G-Assist Hackathon 获得第四名,已上架 NVIDIA 商店。

SwarmX
SwarmX is a scheduler agent framework for large-scale agentic workflow clusters. Submitted to OSDI 2026 and deployed in Tencent WeChat's production environment, it addresses the critical challenge of efficiently scheduling complex AI agent workflows across hundreds of heterogeneous GPUs and millions of CPU cores.SwarmX 是面向大规模 Agentic Workflow 集群的调度 Agent 框架。投稿 OSDI 2026,已在腾讯微信生产环境落地。解决大规模 AI Agent 工作流在数百块异构 GPU 和百万级 CPU 核心上的高效调度难题。
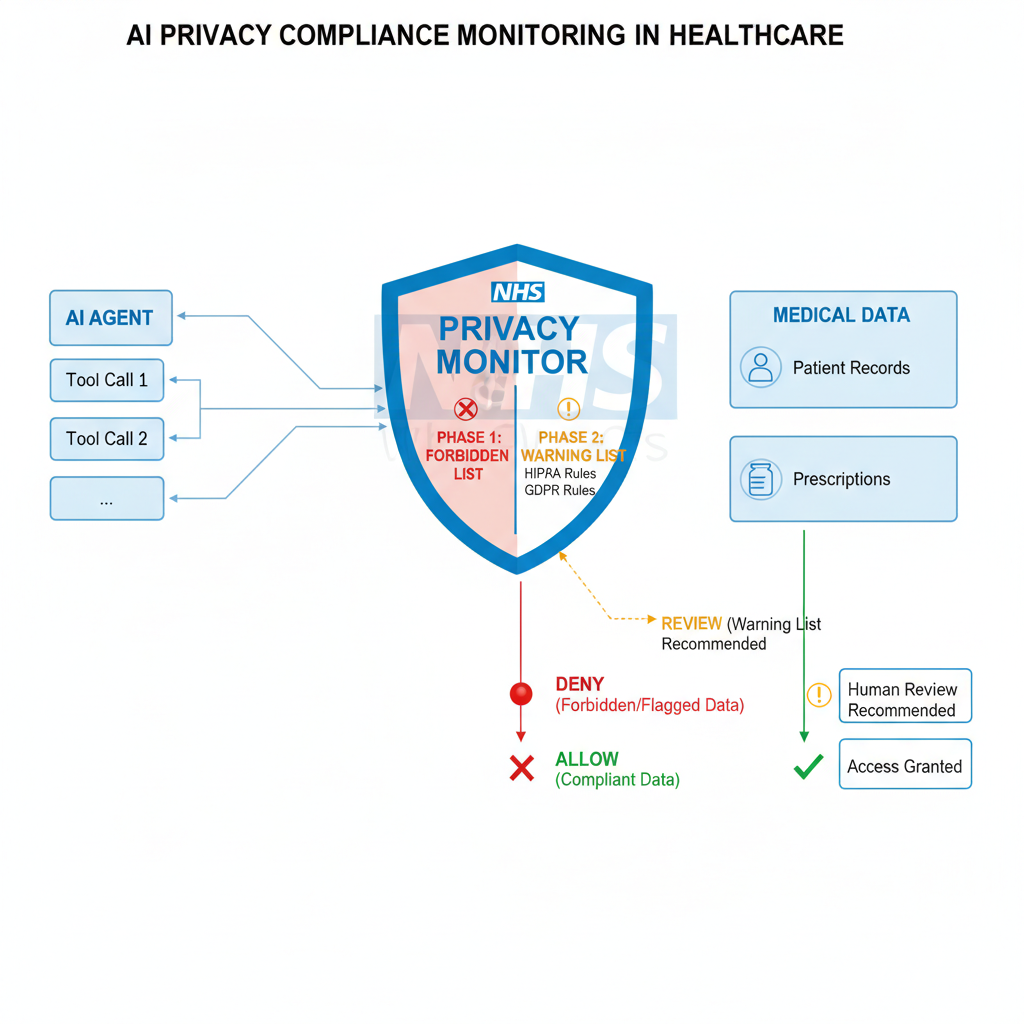
PrivAgent
PrivAgent is an efficient AI agent architecture for real-time privacy risk monitoring in sensitive environments. Developed in collaboration with the NHS (UK National Health Service) Sandbox and submitted to ACL, it solves the critical challenge of ensuring AI agents comply with privacy regulations like HIPAA and GDPR at every action — in real time, not as an afterthought.PrivAgent 是面向隐私敏感环境的高效 AI Agent 实时隐私风险监控架构。与英国国家医疗服务体系(NHS)Sandbox 合作,投稿 ACL。解决 AI Agent 在医疗等隐私敏感场景下,如何在每一次动作执行时实时、高效、可解释地完成 HIPAA/GDPR 等隐私法规合规检查。
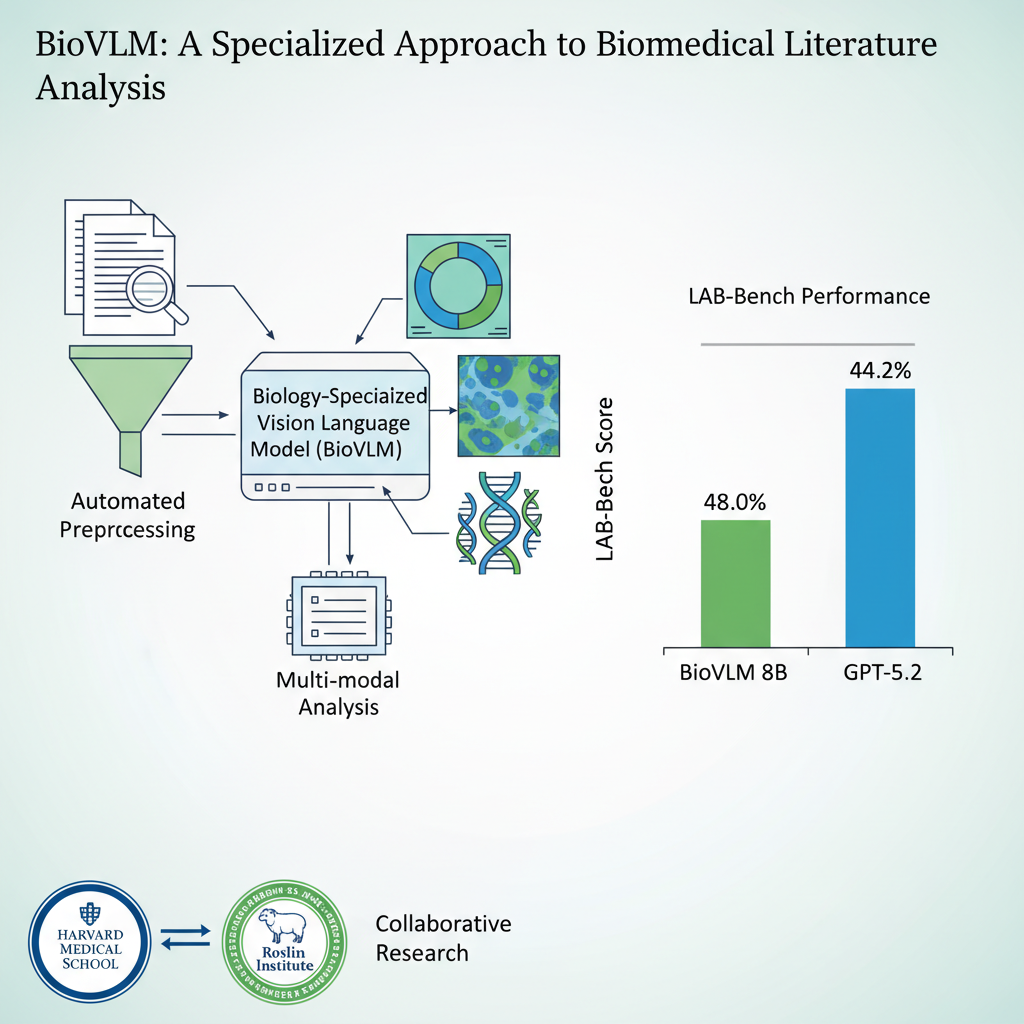
BioVLM
BioVLM is a cost-efficient scientific domain vision-language model that surpasses GPT-5.2 on biological research tasks. Developed in collaboration with Harvard Medical School and Edinburgh's Roslin Institute, it uses automated rich-text data synthesis from raw PDF papers to train a domain-specialized VLM — with the entire pipeline costing less than $200.BioVLM 是低成本自动化训练的生物领域最强图表专家 VLM,超越 GPT-5.2。与哈佛医学院、爱丁堡罗斯林研究所合作,通过自动化富文本数据合成从 PDF 论文直接训练领域专精 VLM,全流程成本低于 $200。
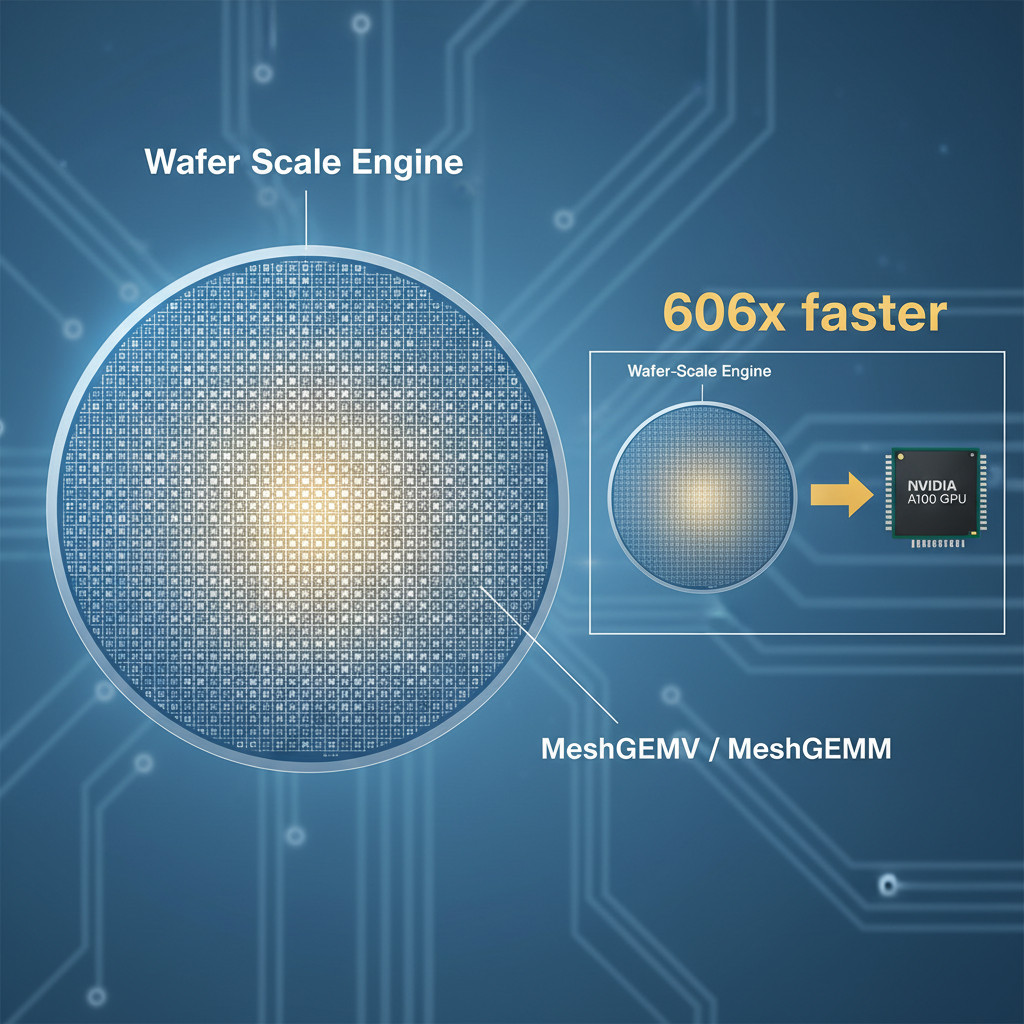
WaferLLM
WaferLLM is the first wafer-scale LLM inference system, designed for a next-generation AI accelerator with hundreds of thousands of cores, tens of gigabytes of distributed on-chip memory, and tens of PB/s on-chip bandwidth. It introduces novel parallel strategies and kernel implementations that achieve orders-of-magnitude performance improvements over GPU-based systems.WaferLLM 是首个晶圆级 LLM 推理系统,面向集成数十万 AI 核心、数十 GB 分布式片上内存和数十 PB/s 片上带宽的新型 AI 加速器。在新型 AI 芯片上实现超越 NVIDIA 数百倍的性能。
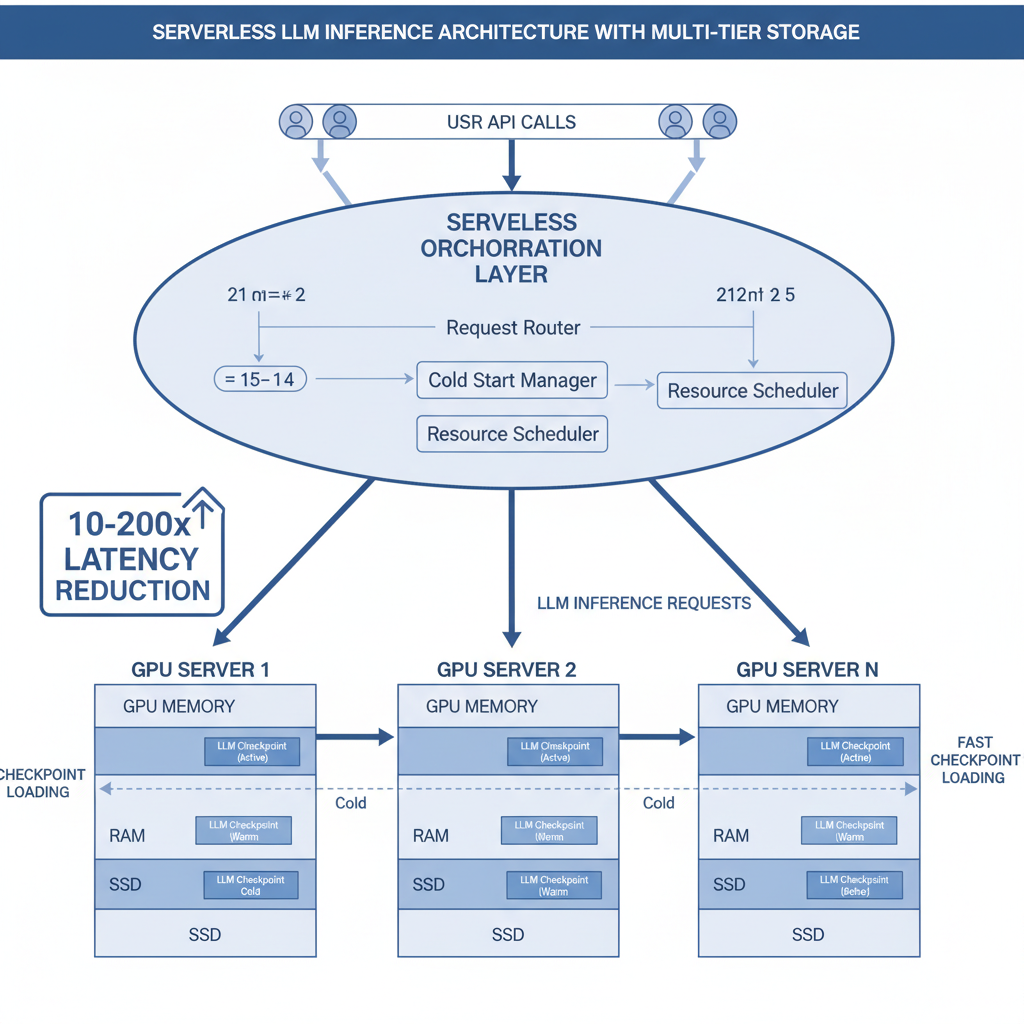
ServerlessLLM
ServerlessLLM is a low-latency serverless inference system for large language models. Its core innovations — multi-tier checkpoint loading, live inference migration, and startup-time-optimized scheduling — have been adopted by nearly every major AI cloud provider, delivering 10–200x latency reductions over state-of-the-art serverless systems.ServerlessLLM 是面向大语言模型的低延迟 Serverless 推理系统。核心创新——多层 checkpoint 加载、活跃推理迁移和启动时间优化调度——已被几乎所有 AI 云厂商采用,实现 10–200× 延迟优化。

MICA
MICA is the first end-to-end compiler for mesh-based AI accelerators. Submitted to OSDI 2026 and developed in collaboration with leading AI chip manufacturers, it enables automatic model adaptation for next-generation AI hardware — turning weeks of manual wafer-scale scheduling into hours of automated compilation, with generated code outperforming expert hand-tuned implementations.MICA 是首个面向 Mesh 架构 AI 加速器的端到端编译器。投稿 OSDI 2026,与领先 AI 芯片厂商联合开发,实现下一代 AI 硬件上的模型自动适配——将原本需要数周的晶圆级调度搜索缩短到数小时,编译器生成的代码甚至超过人类专家手动调优的性能。

ContextPilot
ContextPilot accelerates long-context LLM inference through context reuse — a new paradigm that identifies overlapping context blocks across users and conversation turns to maximize KV-cache reuse while maintaining or even improving inference quality. Developed in collaboration with Tencent.ContextPilot 通过上下文复用加速长上下文 LLM 推理——全新的加速范式,在多用户、多轮对话中识别重叠的上下文块并最大化 KV-cache 复用,同时通过上下文注解技术保持推理质量不降反升。与腾讯合作开发。