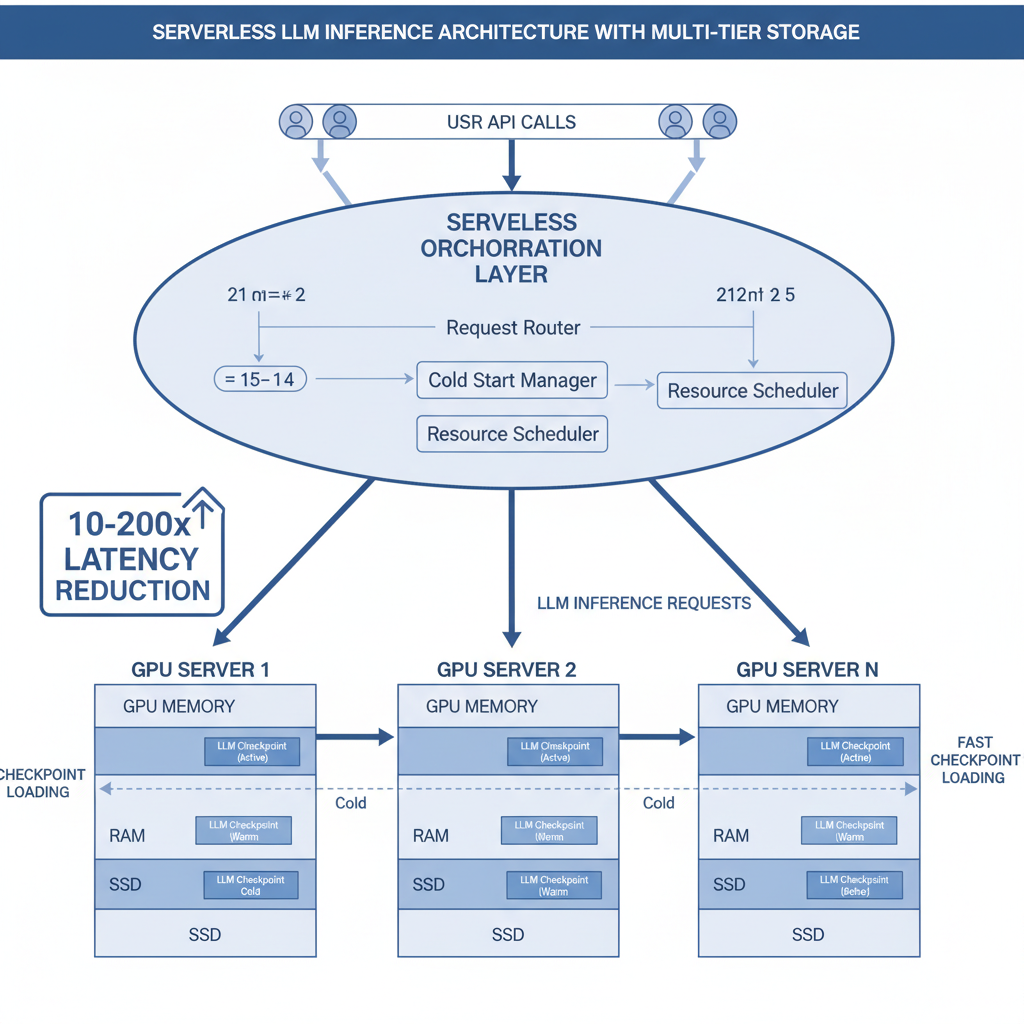
ServerlessLLM is a low-latency serverless inference system for large language models. Its core innovations — multi-tier checkpoint loading, live inference migration, and startup-time-optimized scheduling — have been adopted by nearly every major AI cloud provider, delivering 10–200x latency reductions over state-of-the-art serverless systems.
Key Features
Multi-Tier Checkpoint Loading — A loading-optimized checkpoint format and multi-tier loading system that fully exploits the complex storage hierarchy bandwidth of GPU servers.
Live LLM Inference Migration — Newly started inference can leverage local checkpoint storage while ensuring minimal user disruption.
Startup-Time-Optimized Scheduling — Evaluates checkpoint locality across servers and schedules models to the server with the shortest cold-start time.
Results
- Latency reduced by 10–200x over SOTA serverless systems across various LLM workloads
- Core innovations adopted by nearly every major AI cloud provider
- Three complementary contributions: fast loading solves I/O bottlenecks, live migration solves resource fragmentation, optimized scheduling solves placement decisions
ServerlessLLM 是面向大语言模型的低延迟 Serverless 推理系统。核心创新——多层 checkpoint 加载、活跃推理迁移和启动时间优化调度——已被几乎所有 AI 云厂商采用,实现 10–200× 延迟优化。
核心功能
多层 Checkpoint 快速加载 — 设计加载优化的 checkpoint 格式 + 多层加载系统,充分利用 GPU 服务器复杂存储层级的带宽。
LLM 推理活跃迁移 — 新启动的推理可利用本地 checkpoint 存储,同时确保对用户的最小中断。
启动时间优化调度 — 评估各服务器上 checkpoint 的本地性状态,将模型调度到冷启动时间最短的服务器。
成果
- 比 SOTA serverless 系统延迟降低 10–200×
- 核心成果已被几乎所有 AI 云厂商采用
- 三大核心贡献互补:快速加载解决 I/O 瓶颈、活跃迁移解决资源碎片、优化调度解决放置决策