WaferLLM is the first wafer-scale LLM inference system, designed for a next-generation AI accelerator with hundreds of thousands of cores, tens of gigabytes of distributed on-chip memory, and tens of PB/s on-chip bandwidth. It introduces novel parallel strategies and kernel implementations that achieve orders-of-magnitude performance improvements over GPU-based systems.
Key Features
PLMR Performance Model — Captures the unique hardware characteristics of wafer-scale architecture (mesh interconnect, distributed on-chip memory, ultra-high bandwidth) to guide inference optimization.
Wafer-Scale LLM Parallelism — Novel parallel strategies that optimize the utilization of hundreds of thousands of on-chip cores for unprecedented parallel efficiency.
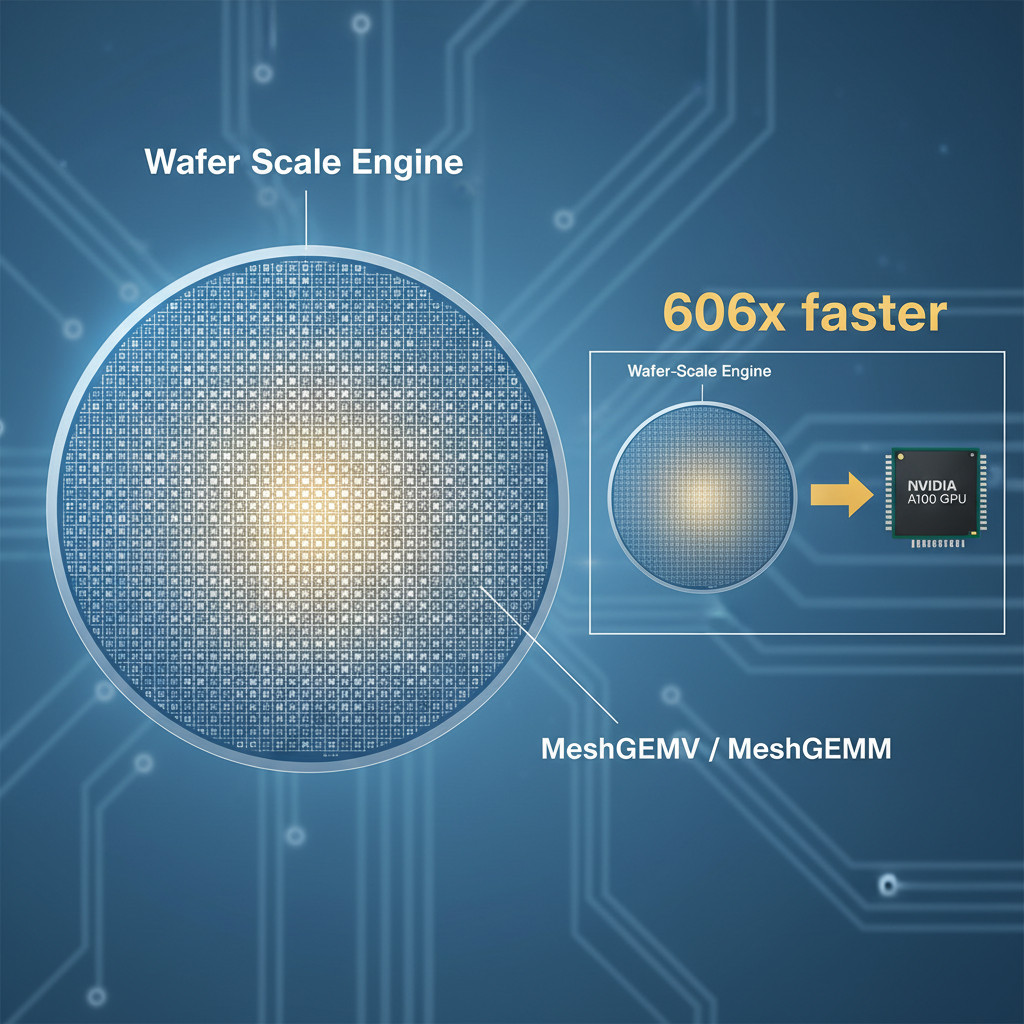
MeshGEMM & MeshGEMV — The first GEMM and GEMV implementations designed for wafer-scale accelerators, scaling effectively across massive core counts.
Results
- GEMV performance: 606x faster than NVIDIA A100, 16x better energy efficiency
- Accelerator utilization: up to 200x over SOTA methods
- End-to-end LLM inference: 10–20x faster than A100 GPU clusters (SGLang/vLLM)
Collaborators
Microsoft Research
WaferLLM 是首个晶圆级 LLM 推理系统,面向集成数十万 AI 核心、数十 GB 分布式片上内存和数十 PB/s 片上带宽的新型 AI 加速器。在新型 AI 芯片上实现超越 NVIDIA 数百倍的性能。
核心功能
PLMR 性能模型 — 捕获晶圆级架构独特的硬件特征(mesh 互连、分布式片上内存、超高带宽),指导推理优化。
晶圆级 LLM 并行 — 全新并行策略,优化数十万片上核心的利用率,实现前所未有的并行效率。
MeshGEMM & MeshGEMV — 首个为晶圆级加速器设计的 GEMM 和 GEMV 实现,可在大规模核心上有效扩展。
成果
- GEMV 性能比 NVIDIA A100 快 606×,能效高 16×
- 加速器利用率比 SOTA 方法高达 200×
- 端到端 LLM 推理比 A100 GPU 集群(SGLang/vLLM)快 10–20×
合作方
微软研究院