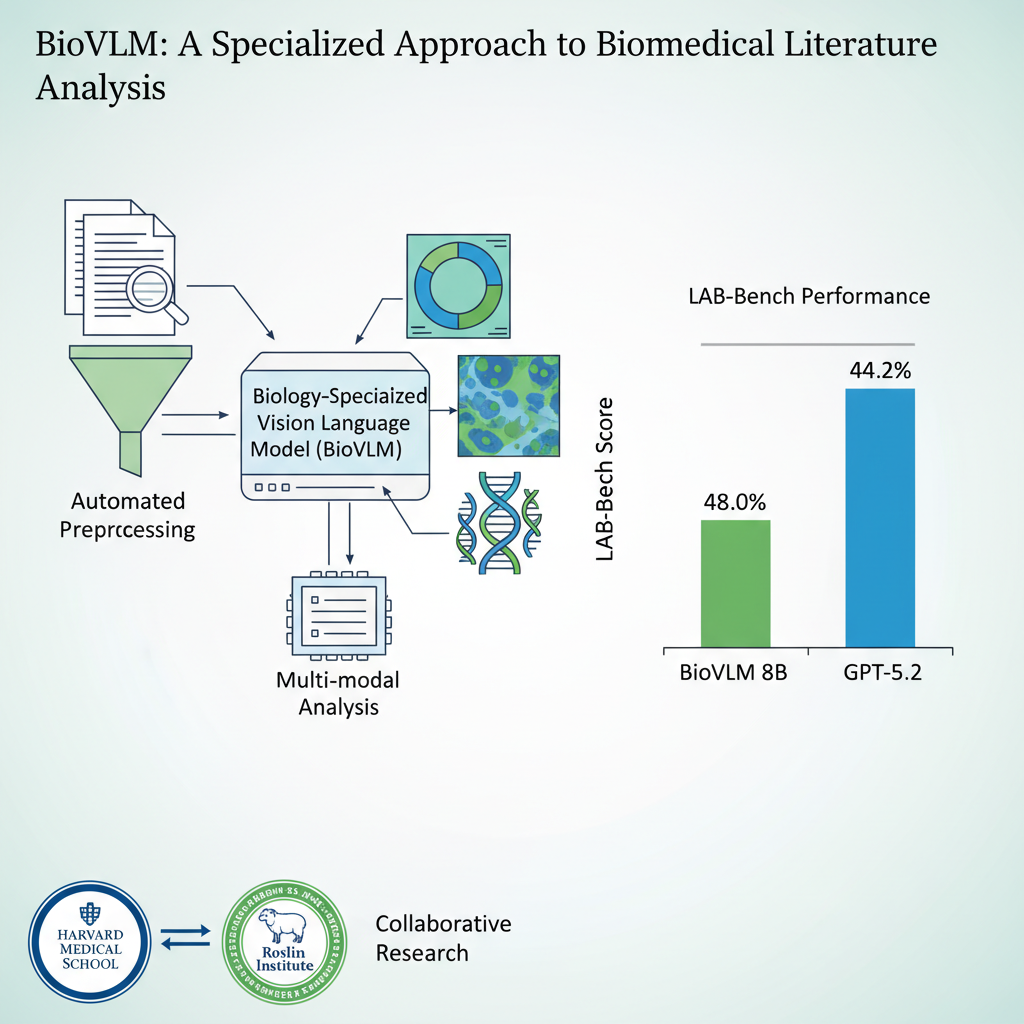
BioVLM is a cost-efficient scientific domain vision-language model that surpasses GPT-5.2 on biological research tasks. Developed in collaboration with Harvard Medical School and Edinburgh's Roslin Institute, it uses automated rich-text data synthesis from raw PDF papers to train a domain-specialized VLM — with the entire pipeline costing less than $200.
Key Features
Anti-Hallucination Document Pipeline — Five-stage processing: layout detection, structured Markdown, cross-reference repair, specialized chart OCR, and hallucination cleaning with terminology correction.
Agentic Data Synthesis — Dual-source question generation from papers and benchmark pattern extraction, with retrieval-augmented answer generation and weakness-driven augmentation.
Two-Stage Training — "Know the Facts" (SFT for domain knowledge injection) followed by "Know the Reasons" (GRPO for reasoning), with no additional human annotation required.
Closed-Loop Evaluation — Automatically detects weak areas, searches PubMed for relevant papers, and iterates training until convergence.
Results
- LAB-Bench weighted accuracy: 48.0% (GPT-5.2: 44.2%, +3.8% improvement)
- Synthetic data outperforms human-annotated data by +14.7 to +17.1% at the same token budget
- Full pipeline cost: < $200 (cloud GPU)
- Trained on ~20,000 PubMed Central open-access papers
Collaborators
Harvard Medical School, Edinburgh Roslin Institute
BioVLM 是低成本自动化训练的生物领域最强图表专家 VLM,超越 GPT-5.2。与哈佛医学院、爱丁堡罗斯林研究所合作,通过自动化富文本数据合成从 PDF 论文直接训练领域专精 VLM,全流程成本低于 $200。
核心功能
抗幻觉文档处理管线 — 五阶段管线:Surya 版面检测→结构化 Markdown→图表交叉引用修复→GLM-OCR 专项图表解析→Qwen3 幻觉清洗与术语修复。
Agentic 数据合成管线 — 双源问题生成(论文原文 + 评测 Benchmark 模式提取)+ 检索增强答案生成 + 弱点驱动增强 + 自动数据充分性检测。
两阶段训练 — "Know the Facts"(SFT 注入领域信息)→"Know the Reasons"(GRPO 训练推理能力),无需额外人工标注。
闭环评估与反馈 — 自动检测模型薄弱领域,从 PubMed 搜索相关论文补充训练,迭代至收敛。
成果
- LAB-Bench 加权准确率 48.0%(GPT-5.2: 44.2%,超越 +3.8%)
- 合成数据比人工数据集高出 +14.7 到 +17.1%(同 token 预算)
- 全流程成本 < $200(云 GPU)
- 训练数据:~20,000 篇 PubMed Central 开放获取论文
合作方
哈佛医学院、爱丁堡罗斯林医学研究所